Introduction
Akumina is the leading global Employee Experience Platform (EXP) software provider. Akumina’s EXP operates by leveraging the Microsoft Azure cloud, Microsoft’s cloud productivity suite, and Microsoft’s Office 365 cloud. Akumina maintains a industry-accepted Business Continuity Program (“BCP”) which ensures that our Customer’s Business is not affected by any interruption. The BCP is functionally continuous and able to meet Akumina’s stated Service Level Agreements with its Customer’s. Akumina’s BCP restores standard operating procedures for its software platform including AppManager, ServiceHub, Employee Experience Platform Base, and Headless solutions.
In the event of a disaster occurring inside of Microsoft’s Cloud, our primary goals of this plan are the following:
• Minimize interruptions to normal operations.
• Limit the extent of disruption and damage.
• Minimize the economic impact of the interruption.
• Establish alternative means of operation in advance.
• Train personnel with emergency procedures.
• Provide for rapid restoration of service.
Akumina’s cloud service architecture leverages shared compute resources, including Azure App Service, Azure Functions, and Batch processing, alongside shared data storage solutions such as Azure Cosmos DB and Azure Storage. This page outlines the technical architecture of the application’s disaster recovery strategy, ensuring alignment with Akumina’s official Business Continuity Plan (BCP).
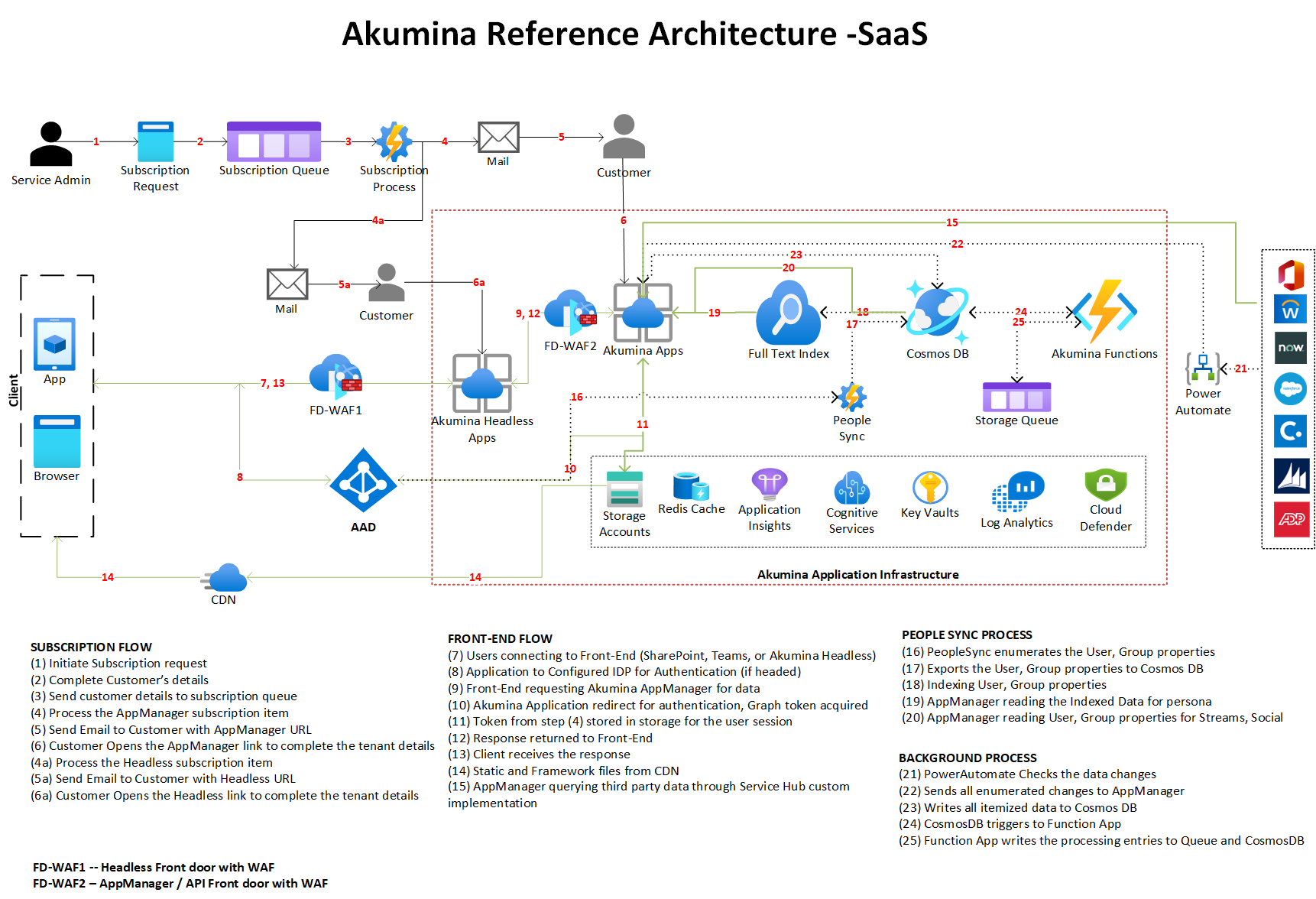
Architecture
Architecture of Akumina Cloud Services Deployed on Microsoft Azure.
SLA and Uptime
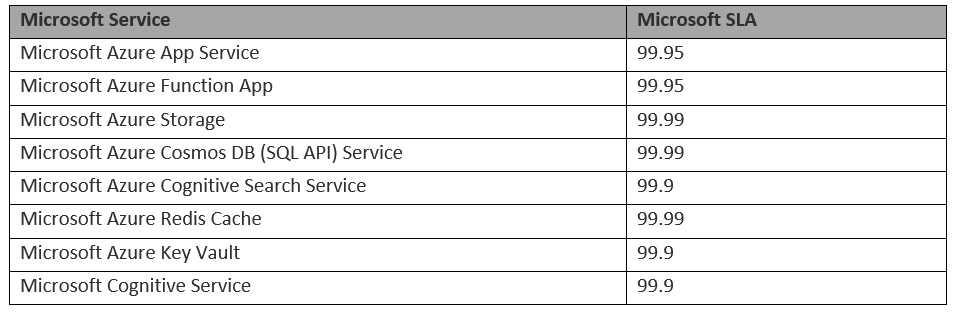
As part of Akumina EXP subscription purchase, each Akumina customer has agreed to Akumina’s Service Level Agreement (SLA), which is contingent on the uptime provided by Microsoft Azure Services. Please note that the table below is provided for informational purposes only. For the most current details on Microsoft’s uptime and SLA, refer to the Microsoft Service Level Agreement at https://azure.microsoft.com/en-us/support/legal/sla/
Furthermore, beyond the uptime assurances provided by Microsoft, Akumina establishes a scheduled maintenance window. This period is designated to occur outside of standard business hours and will be communicated in advance to customers. Akumina’s maintenance window is allocated to maximum of 4 hours monthly.
Disaster Recovery for Multi-Region AppManager
Multi-Region AppManager
Akumina’s top priority is to provide business resilience and continuity. Disaster recovery plans as defined by the BCP are built carefully to minimize the business impact of natural and human-made disasters such as power outages, catastrophic software failures, and network outages. Akumina employs a multi-region strategy that is deployed with backup in geographically distributed Microsoft Azure data centers (regions). When the physical infrastructure in one region is unavailable, the service can still be continued in another region. Akumina cannot guarantee uptimes as it relates to Customer’s networks, the Internet’s performance, Acts of God, and anything else outside of Akumina’s direct control.
Backing up data
Microsoft Azure Storage: Akumina stores configurations into Azure Storage in Blob and Tables. Azure Storage Queues are used for background entries such as Content distribution, streams, people sync etc. Akumina leverages the Azure Storage Geo-Redundant Storage feature to enable a secondary endpoint. In this case, Microsoft replicates data to a secondary region. In addition, Akumina also enables continuous vault backup for the Blob containers.
Microsoft Cosmos DB (SQL API): Microsoft Cosmos DB (SQL API) is used to store Akumina application data such as users, groups, streams, and social data. Akumina configures Cosmos data replication to at least two regions (i.e., 2 X 4 replicas) for high availability.
Application Files: Application files are updated using the package URL or DevOps, and a second region is always deployed using the same package URL to keep both primary and secondary application files consistent.
Backup strategy
Akumina carefully evaluated the following approaches:
• Redeploy on disaster: In this approach, the AppManager and other services redeployed from scratch at the time of disaster.
• Warm Spare (Active/Passive): A secondary hosted service is created in an alternate region, and related services are deployed to guarantee minimal capacity; however, the secondary services do not receive production traffic.
• Hot Spare (Active/Active): The application is designed to receive a production load in multiple regions. All required services in multiple regions are configured for higher capacity than needed for disaster recovery purposes. Alternatively, the cloud services might scale-out as necessary at the time of a disaster and failover.
At Akumina, we have implemented an Active/Active configuration for all our services hosted on Microsoft Azure.
Failover
Akumina’s disaster recovery framework incorporates Azure Front Door to ensure resilient failover mechanisms across regions. By leveraging Azure Front Door’s advanced routing and load balancing, Akumina enhances its application’s availability and reliability even in the event of regional disruptions.
Disaster Recovery Plan
Recovery Point Objective (RPO)
Akumina utilizes geo-redundant storage for all configuration, data and files to minimize the risk of data loss and ensure high availability.
Recovery Time Objective (RTO)
Akumina estimates a recovery response time of under one hour, which encompasses the failover process for Azure Storage.
Failover and failback testing:
Akumina conducts failover and failback testing annually, adhering to the procedures outlined in our Business Continuity Plan (BCP) policy.